ChatGPT és adatvédelem – békíthetetlen ellentétek?

A ChatGPT népszerűsége 2022 november végi megjelenése óta folyamatosan nő. Alig két hónappal a megjelenése után elérte a 100 millió felhasználót, amivel a leggyorsabban növekvő alkalmazássá vált, megelőzve a Tik-Tokot (9 hónap) és az Instagramot (2 és fél év). Mára felhasználói bázisa meghaladja az 1.16 milliárdot.
Az OpenAI által fejlesztett chat-alkalmazás bámulatos térnyerése egyrészt köszönhető annak, hogy rendkívül egyszerű használni, alapfunkciói ingyenesen használhatóak, párbeszéd formájában képes az emberihez hasonló – a legtöbb esetben – sokoldalú és pontos válaszok generálására számos területen.
A tömeges használatával egyidejűleg felmerültek már etikai, adatvédelmi és megbízhatósági aggályok. Például kérdéses, hogy mennyire etikus a ChatGPT-t használni szakdolgozatok, irodalmi művek, szoftverek vagy más szellemi alkotások létrehozásában. Megalapozott félelem az is, hogy az alkalmazás segítségével csalók rendkívül gyorsan képesek hitelesnek tűnő és célszemélyre szabott szövegeket generálni adathalász-támadásokhoz. Az online csalások felturbózása mellett a hihetőnek hangzó, de valójában hibás, pontatlan, elfogult vagy diszkriminatív válaszok által okozott kár is valós kockázatként jelenik meg.
Ez a cikk a ChatGPT-vel kapcsolatos adatvédelmi kérdésekre fókuszál, de ezek szorosan kapcsolódnak az előbb említett, és korábban részletesen tárgyalt etikai és megbízhatósági aggályokhoz.
Márciusban nagy visszhangot váltott ki a hír, hogy az olasz adatvédelmi hatóság (Garante) a ChatGPT olaszországi használatának blokkolásáról döntött. A nagy nyilvánosság előtt ekkor kerültek fókuszba először a ChatGPT működését érintő adatvédelmi kérdések, habár adatvédelmi szakemberek már korábban felhívták a figyelmet a lehetséges problémákra.
Miért „tiltották be” a ChatGPT használatát Olaszországban?
A Garante a felfüggesztés kapcsán kiadott március 31-i sajtóközleményében az adatok biztonságának megsértése – az OpenAI március 20-án jelentett be egy adatvédelmi incidenst, amely a ChatGPT Plus előfizetők egy részét érintette – mellett azt kifogásolta, hogy az OpenAI nem rendelkezik megfelelő jogalappal a személyes adatok tömeges gyűjtéséhez és használatához, amelyet a platform alapjául szolgáló nagy nyelvi modellek (large language models, LLMs) tanítása érdekében folytat. Erről nem biztosít tájékoztatást sem az adatgyűjtésben érintettek, sem felhasználók számára. Továbbá, a ChatGPT hibás, pontatlan vagy félrevezető válaszaira hívta fel a figyelmet. Végül, a regisztrációs folyamat életkor-ellenőrzési mechanizmusát hiányolta. Enélkül bárki, aki egy e-mail címmel rendelkezik tud regisztrálni, illetve tudja használni a ChatGPT szolgáltatást. Ezáltal a gyermekek ki vannak téve annak, hogy életkoruknak és érettségüknek egyáltalán nem megfelelő válaszokat kapnak, annak ellenére, hogy a ChatGPT szolgáltatási feltételei szerint a 13 év felettieknek szól.
Azóta a német, francia, spanyol és ír adatvédelmi hatóság is elkezdte vizsgálni a ChatGPT adatkezeléseinek jogszerűségét. Sőt, az EU-s adatvédelmi hatóságok munkáját felügyelő és összehangoló Európai Adatvédelmi Testület létrehozott egy külön, ChatGPT-vel foglalkozó munkacsoportot. De az amerikai szövetségi versenyjogi hatóság, a Federal Trade Commission (FTC) is kivizsgálást indított a beérkezett panaszok eredményeként. A romániai adatvédelmi hatóság, az ANSPDCP nem tájékoztatott arról, hogy hivatalból indított-e kivizsgálást az ügyben. Amennyiben panasz érkezik a hatósághoz, akkor mindenképpen köteles lesz megvizsgálni a ChatGPT adatkezelési gyakorlatát.
Időközben néhány hiányosság pótlása és a hatósággal való együttműködés következtében a Garante április 28-án bejelentette a ChatGPT felfüggesztésének feloldását.
Ez azt jelenti, hogy a ChatGPT eloszlatta a kételyeket, már a GDPR előírásainak megfelelően működik?
Az adatvédelmi szakemberek többsége, jómagam is beleértve, másképp gondolja. Másrészt, a Garante folytatja a kivizsgálást a hatályos jogszabályok esetleges megsértésének megállapítása érdekében, és a folyamatban lévő tényfeltárás befejezése után dönthet további intézkedésekről. De ne felejtsük el, hogy számos más hatóság nagyítója alá került a ChatGPT adatkezeléseinek vizsgálata.
Három részre lehet osztani a kockázatokat:
- a ChatGPT motorját képező nyelvi modellek személyes adatokkal (is) való tanításának következményei,
- a ChatGPT működéséhez szükséges adatkezelési műveletek adatvédelmi hiányosságai,
- illetve a ChatGPT nem rendeltetésszerű használata, például eszközként kibertámadásokhoz vagy csalásokhoz.
1. A ChatGPT motorját képező nyelvi modellek személyes adatokkal (is) való tanításának következményei
A ChatGPT motorját eredetileg az OpenAI GPT-3 modelljének továbbfejlesztett, GPT-3.5 néven ismert változata adta. A GPT-3 a jelenleg ismert legnagyobb nyelvi modell, 175 milliárd paraméterrel, amelyet 570 gigabájtnyi szövegen tanítottak be. A tanítási adathalmaz részét képező adatok jellemzően az internetről származó szövegek, melyek forrása többek között weboldalak, cikkek, fórumok, könyvek és más nyilvánosan hozzáférhető információtárak.
Fontos megjegyezni, hogy a GPT-3, valamint hasonló modellek tanítási adathalmazába (training dataset) az adatok különösebb emberi ellenőrzés vagy válogatás nélkül kerülnek összegyűjtésre. Ebből két dolog következik. Az interneten fellelhető adatok természetéből fakadóan a tanítási adathalmaz tartalmazhat torzításokat, elfogultságot (bias), pontatlanságokat, és kifogásolható információkat, amelyek a ChatGPT válaszaiban véletlenszerűen tükröződhetnek. Erre fel is hívja a figyelmet a ChatGPT.
Az adatok forrásának következménye az is, hogy a tanítási adathalmaz hatalmas mennyiségű személyes adatot is tartalmaz. Egyes szakemberek szerint, ha valaha közzétettünk nyilvánosan angol nyelvű tartalmat, akkor azt jó eséllyel felhasználták a GPT-3 tanításához. A személyes adatok ilyen célú automatikus gyűjtése és felhasználása esetén felmerül a GDPR előírásainak megsértése. Az adatvédelmi joggyakorlat alapján aligha mondható törvényesnek ilyen nagy mennyiségű személyes adat emberi beavatkozás nélkül történő rendszeres (a nyelvi modelleket folyamatosan tanítják és fejlesztik) kezelése az érintett személyek hozzájárulása nélkül. Továbbra is fennáll a Garante megállapítása, miszerint az OpenAI nem rendelkezik megfelelő jogalappal a személyes adatok ilyen célú kezeléséhez.
Elengedhetetlen lenne az átfogó tájékoztatás is azok számára, akiknek az online elérhető személyes adatai bekerültek a tanítási adathalmazba. Az adatvédelmi alapelvekkel, mint az adattakarékosság, a korlátozott tárolhatóság és a pontosság, is nehezen összeegyeztethető a ChatGPT működése. Mivel a mesterséges intelligencia természetéből adódóan adatéhes, a legtöbb AI-alapú rendszer nem tud mit kezdeni a személyes adatok védelmének alapját képező elvekkel. A ChatGPT konkrét emberekkel kapcsolatos pontatlan válaszainak egyik fő oka, hogy az online elérhető információk alapértelmezetten nem pontosak, hibásak vagy félrevezetőek lehetnek. A másik fő ok, hogy amikor valami személyes dolgot teszünk közzé az interneten, az szükségszerűen kapcsolódik ahhoz a kontextushoz, amelyet a közzétételhez választottunk. Ha az adatokat kiragadják ebből a kontextusból, akkor hiányos képet adhatnak rólunk, vagy akár téves következtetésekhez vezetnek. Ilyen esetekre szokták mondani, hogy „fantáziál” a ChatGPT.
Nem utolsósorban, adatbiztonsági szempontból is lehetnek kételyeink. Kutatók már bizonyították, hogy a nyelvi modellek lekérdezése során lehetséges adatokat kinyerni a tanítási adathalmazból. Például, a GPT-2 elleni „támadásuk” során képesek voltak személyazonosításra alkalmas adatokat (nevek, telefonszámok és e-mail címek) megszerezni.
Az alapelveken és megfelelő tájékoztatáson túl felmerül, hogy a GDPR további előírásait – mint az adatvédelmi hatásvizsgálat elvégzése, kockázatarányos adatvédelmi intézkedések beépítése, adatvédelmi incidensek kezelése, vagy a nemzetközi adattovábbításokra vonatkozó követelményeket – figyelembe vették-e a ChatGPT fejlesztésekor. Az sem egyértelmű, hogy képes lesz-e a ChatGPT megfelelni az EU közelgő mesterséges intelligenciát szabályozó rendeletének, az AI Act-nek megfelelni.
2. A ChatGPT működéséhez szükséges adatkezelési műveletek adatvédelmi hiányosságai
Az európai adatvédelmi hatóságok által kifogásolt adatkezelési gyakorlatokból néhány továbbra is aktuális.
A ChatGPT-re való regisztráció során elégséges az e-mail cím mellett egy 8 karakter hosszúságú jelszó. Már a minimális hosszúság eltér a jelszóbiztonsági standardoktól (legalább 12-16 karakter), továbbá elégséges bepötyögni 1-től 8-ig a számokat, nem kell kötelezően tartalmazzon a számok mellett kis- és nagybetűt, illetve szimbólumot. Az így létrejött kevésbé komplex jelszavakkal rendelkező fiókokat sokkal könnyebben törhetik fel és élhetnek vissza vele rosszindulatú felek. Annak is köszönhetően, hogy a kétlépcsős azonosítás nem alapértelmezett, hanem a felhasználó beállításán múlik.
A ChatGPT felhasználási feltételei értelmében a szolgáltatás 13 év feletti személyeknek szól. A regisztráció során ezt úgy ellenőrzi a rendszer, hogy elkéri a születési dátumot és ez alapján kiszámolja, hogy teljesítjük-e a korhatár feltételeit.
Ahogy az olasz hatóság is kifogásolta, ezt roppant egyszerű kijátszani. Másrészt, az OpenAI azt mondja, hogy szülői hozzájárulás szükséges a 13-18 év közötti kiskorúak esetében a ChatGPT használatához. De valójában ezt a hozzájárulást a rendszer nem kéri, a szülőnek nincs lehetősége beleegyezni, hanem az OpenAI a felhasználóra bízza, hogy teljesíti-e a korhatár feltételeit és rendelkezik-e szülői hozzájárulással. Ez a gyakorlat rendkívül aggályos. Lehetővé teszi, hogy kortól és szülői hozzájárulás meglététől függetlenül bármely e-mail címmel rendelkező kiskorú regisztráljon ChatGPT-felhasználóként.
A ChatGPT használata során azzal találkozhatunk, hogy alapértelmezetten az OpenAI felhasználja az elmentett chat előzményeink a nyelvi modellek további tanításához. Egyrészt, az előzmények megőrzése automatikusan össze van kötve azzal, hogy ezeket felhasználják a fejlesztésekhez. Ha ezt kikapcsoljuk, akkor 30 nap után törlődnek automatikusan a kérdéseink (prompt-jaink) és az ezekre kapott válaszaink. Ez egy úgy nevezett dark pattern, amellyel az OpenAI arra készteti a felhasználókat, hogy ne tiltakozzanak adataik felhasználása ellen.
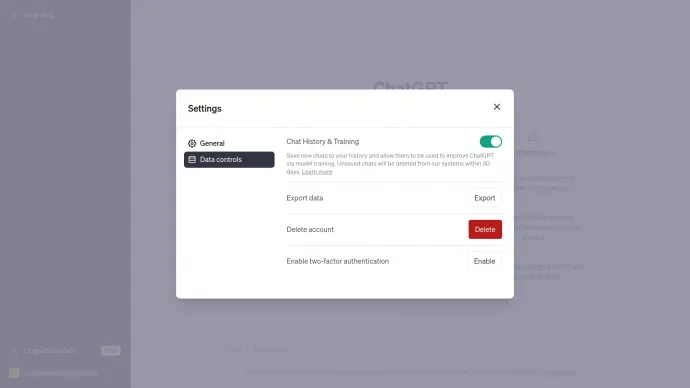
Ez a megközelítés szembemegy a beépített és alapértelmezett adatvédelem (Data Protection by Design and by Default) előírásával a GDPR-nak. De kérdéses az is, hogy teljesíti-e a jogos érdek alapú adatkezelés feltételeit, mint a szükségesség és arányosság.
3. A ChatGPT használata adathalászathoz és kibertámadásokhoz
Számos kutatás és cikk született már azzal kapcsolatosan, hogy a ChatGPT használható jogellenes tevékenységek megvalósítására. A leggyakrabban említett példa, hogy az adathalászok könnyedén készíthetnek hitelesnek tűnő e-maileket adathalász támadásokhoz vagy más illegális tevékenységekhez. Ennek köszönhetően a nyelvi akadályok vagy a helyesírási hibák sem jelentenek akadályt a csalók előtt, és kifinomultabbá válnak az adathalászkísérletek. Egyre nagyobb kihívást jelent a valódi és az adathalász e-mailek megkülönböztetése.
A ChatGPT-hez hasonló szolgáltatások képesek adatok átfogó összegyűjtésére, például egy vállalat vezetőinek névsorának és céges e-mail címüknek összeállítására egy kért fájlformátumban, vagy beazonosítani, hogy ki tölt egy bizonyos pozíciót egy vállalatban. Ez jól mutatja, hogy az ilyen automatizált adatgyűjtés növelheti egy külső támadás sikerét, miközben csökkenti a költségét.
A ChatGPT hatékonyan alkalmazható az egyes technológiákhoz vagy platformokhoz kapcsolódó alkalmazások gyors azonosítására. Ez segíthet az adott hálózati környezet potenciális támadási felületeinek és sebezhetőségeinek felderítésében.
Amikor kutatók a ChatGPT-t arra kérték, hogy vizsgálja meg a sebezhetőségeket egy több mint 100 soros kódmintán belül, akkor pontosan azonosított néhányat. A bizonyítja a ChatGPT potenciálját a biztonsági hibák azonosításában. Ez elősegítheti a külső támadások sikerességét.
Úgy tűnik, mintha nem is tudna megfelelni az adatvédelmi követelményeknek és az adatbiztonsági standardoknak egy AI-rendszer, amely személyes adatokat „zabál”.
Ahogyan egy autóversenyzőnek egyensúlyt kell teremtenie a sebesség és a biztonság között a pályán való sikerhez, úgy a személyes adatok hasznosítására üzleti modellt építő vállalkozásoknak is egyensúlyt kell teremteniük az innováció és a növekedés, valamint a személyes adatok felelősségteljes kezelése között ahhoz, hogy hosszútávon sikeresek legyenek a digitális világban.

A ChatGPT példájára visszatérve, egy több millió dollárból fejlesztett szolgáltatás esetében különösképpen elvárható az OpenAI-tól, hogy a tervezési fázistól kezdve erőfeszítéseket tegyen a személyes adatok védelme, a nem rendeltetésszerű használat megelőzése és az egyéb kockázatok csökkentése érdekében. Annak tükrében még inkább, hogy az OpenAI már nem egy non-profit kezdeményezés, hanem rendkívüli tőkével rendelkező és bevételt generáló vállalat.
A felhasználókon kívül, például a vállalatok számára kockázatot jelenthet-e a ChatGPT használata?
Igen, elsősorban a bizalmas, üzleti titoknak számító vagy egyéb szempontból érzékeny adatok megosztásának kockázata merül fel. Előfordulhat, hogy egy alkalmazott úgy mérlegel, hogy alacsony kockázatot jelent egy bizonyos céges információt az utasítás részeként megadni ChatGPT-nek. Mivel a ChatGPT alapértelmezetten felhasználja a modellek további tanítására az általunk adott utasításokat, előfordulhat, hogy a későbbiekben válaszként jelenik meg egy másik felhasználó számára az általunk megadott információ. Így, nem kívánt célközönséghez, például a konkurenciához is eljuthatnak bizalmas vállalati adatok. Ezzel megsértve a vállalat érdekeit, titoktartási megállapodásokat és esetenként akár törvényszegést eredményezve.
Ezt a kockázatot csökkenti, ha a beállításoknál kikapcsoljuk az utasításaink (prompt-jaink) alapértelmezett felhasználását tanítási adatként. Ennek az a következménye, hogy csak 30 napig tárolja a ChatGPT az utasításaink. Az időtartam rövidsége ellenére egy adatszivárgás következtében a ChatGPT-vel megosztott bizalmas vállalati adatok rosszindulatú felek vagy akár az egész világ számára hozzáférhetővé válhatnak. Ezért előnyös lehet egy vállalati szabályzat a ChatGPT és más generatív AI rendszerek használatára vonatkozóan, illetve az utasítások törlése rövid határidőn belül.
Egy másik potenciális kockázat a szerzői jogok megsértése. Egy kísérlet során már előfordult, hogy a ChatGPT által adott válaszban egy egész oldalnyi szöveg szerepelt egy szakkönyvből hivatkozás nélkül. Egy ilyen válasznak az ellenőrzés nélküli felhasználása jogi következményekkel járhat.
A ChatGPT már említett korlátaiból fakadó hibás, pontatlan, diszkriminatív vagy félrevezető válaszok is súlyos károkat tudnak okozni egy vállalat számára.
A szerző Székely Barnabás, jogász, adatvédelmi szakember, a Privacy Pro alapítója, a GDPR Akadémia trénere.
A nemzetközi minősítésekkel (CIPP/E, CDPSE, ISO 27001 Auditor) rendelkező szakember 2016-tól kezdve számos iparág – e-commerce, szoftverfejlesztés, egészségügy, telekommunikáció, vendéglátás – szereplője támaszkodott tudására nemzetközi és hazai GDPR projektekben, illetve az adatvédelmi incidensek megelőzésében. Barnabás a jogi mellett informatikai háttérrel is rendelkezik. A Madridi Műszaki Egyetem (UPM) és Milánói Műszaki Egyetem (PoliMi) közös mesterképzésén diplomázott mesterséges intelligencia szakon. Disszertációját az AI-alapú rendszerek adatvédelmi kockázatainak kezeléséről írta. Az International Association of Privacy Professionals (IAPP) és az Information Systems Audit and Control Association (ISACA) tagja.
Támogasd a Transtelexet egy kávé árával!
Munkánkkal minden nap magyar közösségeket tartunk képben, teret adunk helyi ügyeknek, és fontos erdélyi történeteket mutatunk be — függetlenül, szabadon. Ahhoz, hogy ezt továbbra is így tehessük, rád is szükségünk van.
Támogatom